Hadoop基本操作
Hadoop基本操作
Hadoop Shell基本操作
实验过程及代码:
- 打开终端模拟器,启动Hadoop开启相关DataNode、NameNode、SecondaryNameNode、Jps等相关进程。
1 | |
- 在Hadoop中创建、修改、查看、删除文件夹test1及文件data.txt。
1 | |
- 使用chown方法,改变Hadoop/test1目录中的data.txt文件拥有者和权限。
1 | |
- 使用Shell命令执行Hadoop自带的WordCount类
1 | |
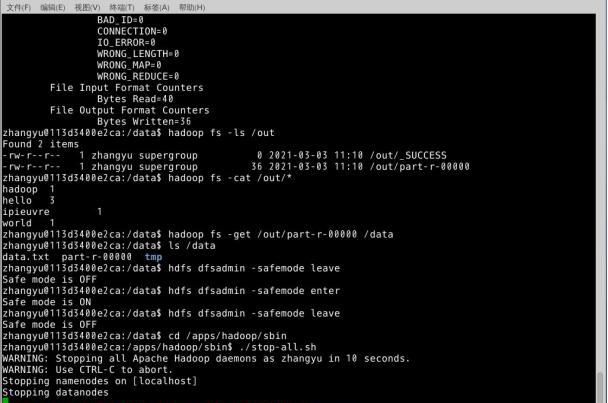
- 进入Hadoop安全模式并退出。
1 | |
HDFS JAVA API
实验过程及代码:
- 在终端模拟器启动Hadoop,创建hadoop4目录,下载依赖包并解压到hadoop4目录;
1 | |
打开Eclipse,新键Java Project,名为hadoop4,新建包my.hdfs,创建目录hadoop4lib存放依赖包,把jar包拷贝并全选,右键点击BuildPath=>Add to Build Path选项加载jar包到项目。
新建类MakeDir,功能:在HDFS的根目录下,创建名为hdfstest的目录。代码如下:
1 | |
hadoop fs -ls -R / // //使用ls -R的方式递归查看根下所有文件
- 新建类TouchFile,功能:在HDFS的目录/hdfstest下,创建名为touchfile的文件.
1 | |
hadoop fs -ls -R / // //使用ls -R的方式递归查看根下所有文件
- cd /data/hadoop4 在/data/hadoop4下
vim sample_data //使用vim打开sample_data文件,
使用vim编辑输入a,开启输入模式
hello world //输入hello world
- 创建类CopyFromLocalFile.class,功能:将本地linux操作系统上的文件/data/hadoop4/sample_data,上传到HDFS文件系统的/hdfstest目录下。代码如下:
1 | |
1 | |
- 新建类ListFiles,程序功能是列出HDFS文件系统/hdfstest目录下,所有的文件,以及文件的权限、用户组、所属用户。
1 | |
执行结果:

- 新建类IteratorListFiles,功能:列出HDFS文件系统/根目录下,以及各级子目录下,所有文件以及文件的权限、用户组,所属用户。
1 | |

- 新建类LocateFile,功能:查看HDFS文件系统上,文件/hdfstest/sample_data的文件块信息。
1 | |
- 新建类WriteFile,功能:在HDFS上,创建/hdfstest/writefile文件并在文件中写入内容“hello world hello data!”。
1 | |
1 | |

- 在linux本地创建/data/hadoop4/testmerge目录。
1 | |
- 新建类PutMerge,功能:将Linux本地文件夹/data/hadoop4/testmerge/下的所有文件,上传到HDFS上并合并成一个文件/hdfstest/mergefile。
1 | |
1 | |

开发YARN客户端应用
实验过程及代码:
- 启动hadoop,下载依赖包。
1 | |
添加项目所需的jar包。
打开Eclipse,新键Java Project,名为YARN,新建包my.yarn,创建目录lib存放依赖包,把jar包拷贝并全选,右键点击BuildPath=>Add to Build Path选项加载jar包到项目。
新建类,类名为Client。
- 客户端编写流程
步骤1 Client通过RPC函数ClientRMProtocol.getNewApplication从ResourceManager中获取唯一的application ID
步骤2 Client通过RPC函数ClientRMProtocol#submitApplication将ApplicationMaster提交到ResourceManager上。
主要作用是提交(部署)应用和监控应用运行两个部分
1 | |
- 新建类,类名为ApplicationMaster。
1 | |
- 代码编写完成后,将整个YARN项目打包成jar包,
在Linux的命令行,切换到/data/yarn目录下
1 | |
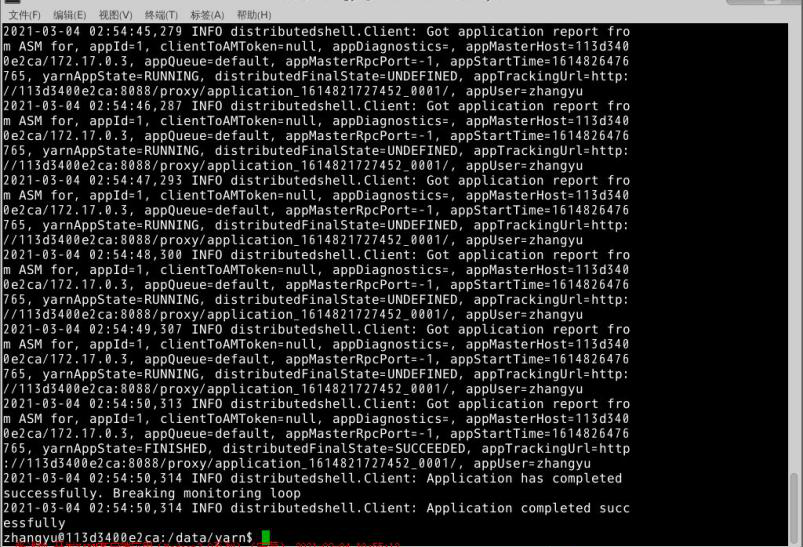
使用下面命令执行distributedshell。
1 | |
执行结果:
相关知识总结
MapReduce介绍
MapReduce采用的是“分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个从节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单来说,MapReduce就是”任务的分解与结果的汇总“。
- MapReduce的工作原理
在分布式计算中,MapReduce框架负责处理了并行编程里分布式存储、工作调度,负载均衡、容错处理以及网络通信等复杂问题,现在我们把处理过程高度抽象为Map与Reduce两个部分来进行阐述,其中Map部分负责把任务分解成多个子任务,Reduce部分负责把分解后多个子任务的处理结果汇总起来,具体设计思路如下。
Map过程需要继承org.apache.hadoop.mapreduce包中Mapper类,并重写其map方法。通过在map方法中添加两句把key值和value值输出到控制台的代码,可以发现map方法中输入的value值存储的是文本文件中的一行(以回车符为行结束标记),而输入的key值存储的是该行的首字母相对于文本文件的首地址的偏移量。然后用StringTokenizer类将每一行拆分成为一个个的字段,把截取出需要的字段(本实验为买家id字段)设置为key,并将其作为map方法的结果输出。
Reduce过程需要继承org.apache.hadoop.mapreduce包中Reducer类,并重写其reduce方法。Map过程输出的<key,value>键值对先经过shuffle过程把key值相同的所有value值聚集起来形成values,此时values是对应key字段的计数值所组成的列表,然后将<key,values>输入到reduce方法中,reduce方法只要遍历values并求和,即可得到某个单词的总次数。
在main()主函数中新建一个Job对象,由Job对象负责管理和运行MapReduce的一个计算任务,并通过Job的一些方法对任务的参数进行相关的设置。本实验是设置使用将继承Mapper的doMapper类完成Map过程中的处理和使用doReducer类完成Reduce过程中的处理。还设置了Map过程和Reduce过程的输出类型:key的类型为Text,value的类型为IntWritable。任务的输出和输入路径则由字符串指定,并由FileInputFormat和FileOutputFormat分别设定。完成相应任务的参数设定后,即可调用job.waitForCompletion()方法执行任务,其余的工作都交由MapReduce框架处理。
- MapReduce框架的作业运行流程
ResourceManager:是YARN资源控制框架的中心模块,负责集群中所有资源的统一管理和分配。它接收来自NM(NodeManager)的汇报,建立AM,并将资源派送给AM(ApplicationMaster)。
NodeManager:简称NM,NodeManager是ResourceManager在每台机器上的代理,负责容器管理,并监控他们的资源使用情况(cpu、内存、磁盘及网络等),以及向ResourceManager提供这些资源使用报告。
ApplicationMaster:以下简称AM。YARN中每个应用都会启动一个AM,负责向RM申请资源,请求NM启动Container,并告诉Container做什么事情。
Container:资源容器。YARN中所有的应用都是在Container之上运行的。AM也是在Container上运行的,不过AM的Container是RM申请的。Container是YARN中资源的抽象,它封装了某个节点上一定量的资源(CPU和内存两类资源)。Container由ApplicationMaster向ResourceManager申请的,由ResouceManager中的资源调度器异步分配给ApplicationMaster。Container的运行是由ApplicationMaster向资源所在的NodeManager发起的,Container运行时需提供内部执行的任务命令(可以是任何命令,比如java、Python、C++进程启动命令均可)以及该命令执行所需的环境变量和外部资源(比如词典文件、可执行文件、jar包等)。
另外,一个应用程序所需的Container分为两大类,如下:
- 运行ApplicationMaster的Container:这是由ResourceManager(向内部的资源调度器)申请和启动的,用户提交应用程序时,可指定唯一的ApplicationMaster所需的资源。
- 运行各类任务的Container:这是由ApplicationMaster向ResourceManager申请的,并为了ApplicationMaster与NodeManager通信以启动的。
以上两类Container可能在任意节点上,它们的位置通常而言是随机的,即ApplicationMaster可能与它管理的任务运行在一个节点上。
- MapReduce将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map和Reduce
- 编程容易,不需要掌握分布式并行编程细节,也可以很容易把自己的程序运行在分布式系统上,完成海量数据的计算
- MapReduce采用“分而治之”策略,一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的分片(split),这些分片可以被多个Map任务并行处理
- MapReduce设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”,因为,移动数据需要大量的网络传输开销
- MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave。Master上运行JobTracker,Slave上运行TaskTracker
- Hadoop框架是用Java实现的,但是,MapReduce应用程序则不一定要用Java来写
MapReduce优势

| 传统并行计算框架 | MapReduce | |
|---|---|---|
| 集群架构/容错性 | 共享式(共享内存/共享存储),容错性差 | 非共享式,容错性好 |
| 硬件/价格/扩展性 | 刀片服务器、高速网、SAN,价格贵,扩展性差 | 普通PC机,便宜,扩展性好 |
| 编程/学习难度 | what-how,难 | what,简单 |
| 适用场景 | 实时、细粒度计算、计算密集型 | 批处理、非实时、数据密集型 |
- Map函数和Reduce函数
| 函数 | 输入 | 输出 | 说明 |
|---|---|---|---|
| Map | <*k*1,v1>如:<行号,”a b c”> | List(<*k*2,*v*2>)如:<“a”,1><“b”,1><“c”,1> | 1.将小数据集进一步解析成一批<key,value>对,输入Map函数中进行处理2.每一个输入的<*k*1,*v*1>会输出一批<*k*2,*v*2>。<*k*2,*v*2>是计算的中间结果 |
| Reduce | <*k*2,List(*v*2)>如:<“a”,<1,1,1>> | <*k*3,*v*3><“a”,3> | 输入的中间结果<k*2,List(v2)>中的List(v2)表示是一批属于同一个k*2的value |
MapReduce体系结构主要由四个部分组成,分别是:Client、JobTracker、TaskTracker以及Task
- Client
用户编写的MapReduce程序通过Client提交到JobTracker端
用户可通过Client提供的一些接口查看作业运行状态- JobTracker
JobTracker负责资源监控和作业调度
JobTracker 监控所有TaskTracker与Job的健康状况,一旦发现失败,就将相应的任务转移到其他节点
JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器(TaskScheduler),而调度器会在资源出现空闲时,选择合适的任务去使用这些资源 - Client
用户编写的MapReduce程序通过Client提交到JobTracker端
用户可通过Client提供的一些接口查看作业运行状态 - JobTracker
JobTracker负责资源监控和作业调度
JobTracker 监控所有TaskTracker与Job的健康状况,一旦发现失败,就将相应的任务转移到其他节点
JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器(TaskScheduler),而调度器会在资源出现空闲时,选择合适的任务去使用这些资源
- JobTracker
MapReduce工作流程
不同的Map任务之间不会进行通信
不同的Reduce任务之间也不会发生任何信息交换
用户不能显式地从一台机器向另一台机器发送消息
所有的数据交换都是通过MapReduce框架自身去实现的
MapReduce执行的全过程包括以下几个主要阶段:
从分布式文件系统读入数据
执行Map任务输出中间结果
通过 Shuffle阶段把中间结果分区排序整理后发送给Reduce任务
执行Reduce任务得到最终结果并写入分布式文件系统。
MapReduce具有广泛的应用,比如关系代数运算、分组与聚合运算、矩阵-向量乘法、矩阵乘法等。
Woooohhhhhh! Finally!!!