An Introduction to Diffusion Models
扩散模型
什么是扩散模型
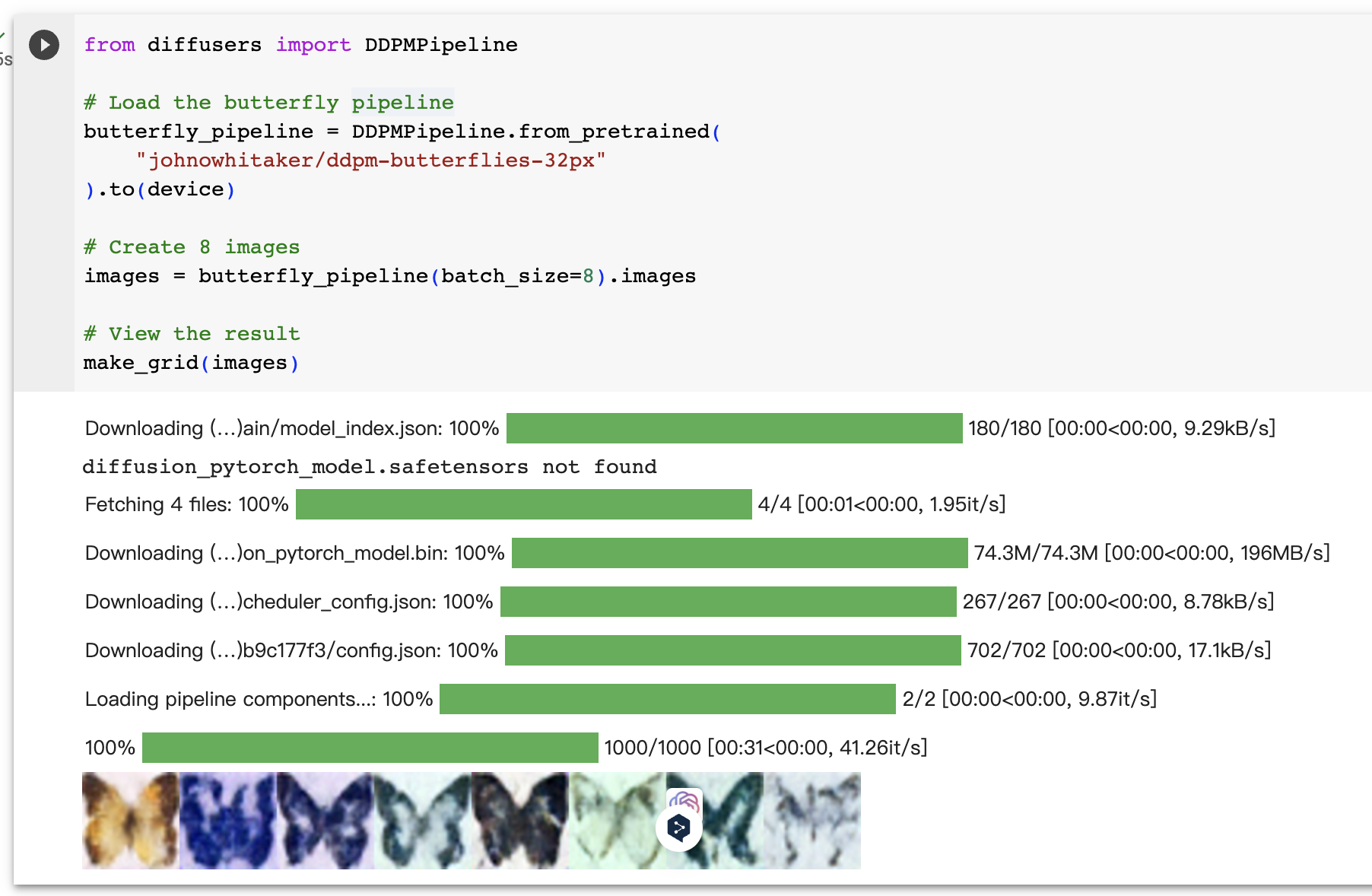
生成模型,从纯噪声开始逐渐去躁数据。
标志
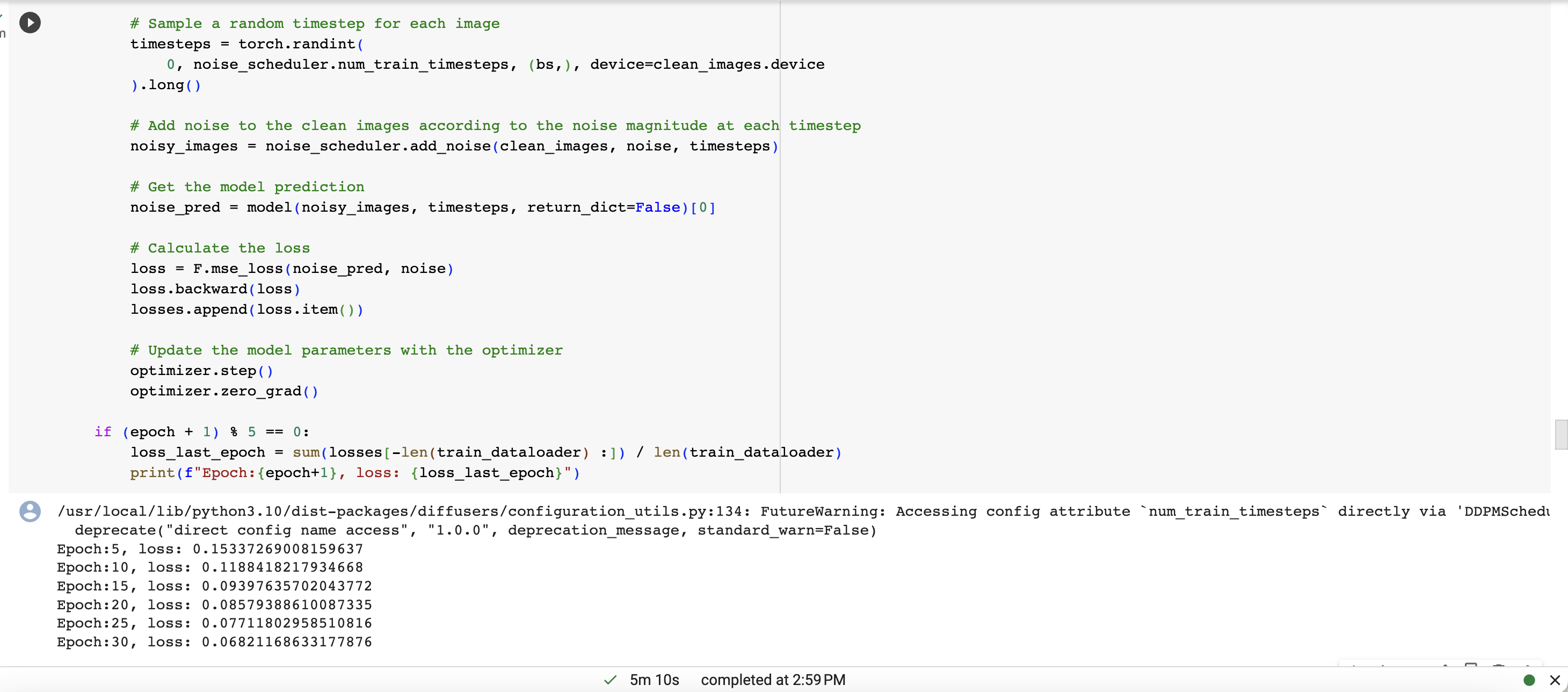
从纯噪音开始进行迭代细化,这种缓慢的渐进去躁是扩散模型的标志,一开始生成的是随机噪声,但经过若干步骤后,噪声会逐渐细化,直到出现输出图像。在每一步中,模型都会估算如何将当前输入图像转化为完全去噪的版本,最终模型输出和当前样本的某种组合
迭代特性
以迭代细化方式训练模型,并通过进行多次预测并每次移动少量来对其进行采样,直到获得类似的去噪输出。
环境准备
1 | |
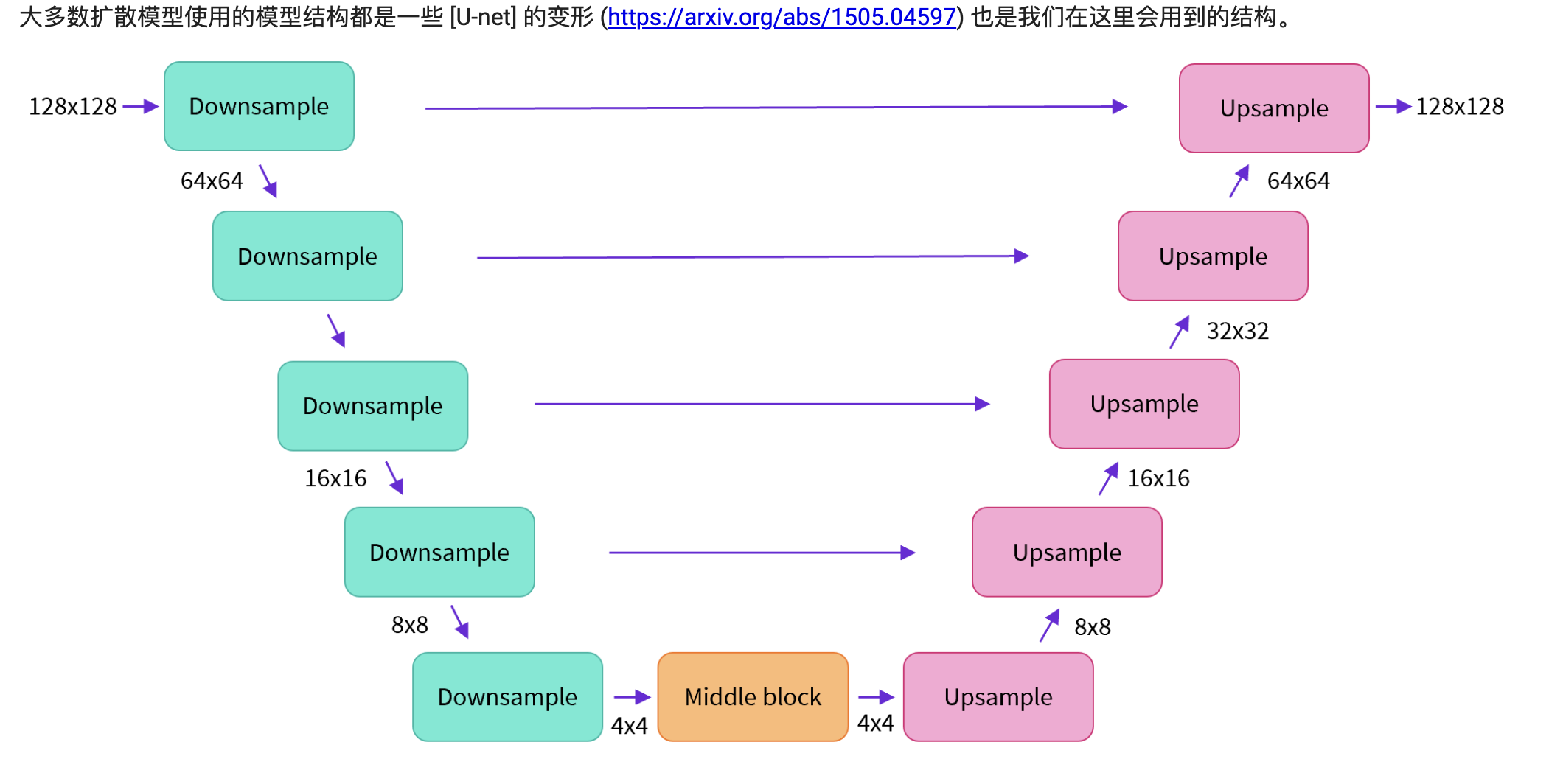
U-Net模型代码
典型的Encoder-Decoder结构,加入了时序建模的时间embedding和条件对比机制。利用ResNet块提取特征,自注意力层进行全局交互,上下采样调整分辨率。
1 | |
定义模型 GPU计算
1 | |
输入模型中的图片经过几个由 ResNetLayer 构成的层,其中每层都使图片尺寸减半。之后在经过同样数量的层把图片升采样。其中还有对特征在相同位置的上、下采样层残差连接模块。模型一个关键特征既是,输出图片尺寸与输入图片相同.
生成的图像结果代码处理逻辑学习理解
1 | |
相关参数
在使用Diffusion生成图片时调整参数以获取更好效果,可以从以下几个方面调整:
num_inference_steps: 推理步数,值越大生成的图片质量越高,但速度越慢。一般50-100是一个合理的范围。
guidance_scale: 指导尺度,控制文本prompt的作用力。值越大对prompt越忠实。7-15是一个合适的范围。
cfg_scale: CLIP模型作用力,可以增强生成图片的逼真度和识别能力。默认值是7,可以尝试增加到10左右。
Height/Width: 生成图片分辨率,越大则细节越丰富,但消耗越大。
Batch size: 一次生成的图片数量,对显卡影响很大,根据环境调整。
优化模型超参数
计算FID是评估生成图片质量的常用定量指标,可以用来优化模型超参数。
通过以下方式计算生成图片的FID(Frechet Inception Distance)分数:
- 导入必要的包:
1 | |
- 加载预训练好的Inception v3模型来进行特征提取:
1 | |
- 将生成的图片读取为PIL Image对象,构建一个images列表
1 | |
- 计算images与真实图片集的FID score:
real_imgs = load_real_images() # 载入真实图片
fid = FID.calculate_fid(model, real_imgs, images)较低的fid分数表示生成图片的分布更接近真实图片集。
或者直接使用diffusers库中的FIDScore评估器类进行计算。
Diffusers 的核心 API 三个主要部分:
- 管道: 从高层出发设计的多种类函数,旨在以易部署的方式,能够做到快速通过主流预训练好的扩散模型来生成样本。
- 模型: 训练新的扩散模型时用到的主流网络架构,e.g. UNet.
- 管理器 (or 调度器): 在 推理 中使用多种不同的技巧来从噪声中生成图像,同时也可以生成在 训练 中所需的带噪图像。

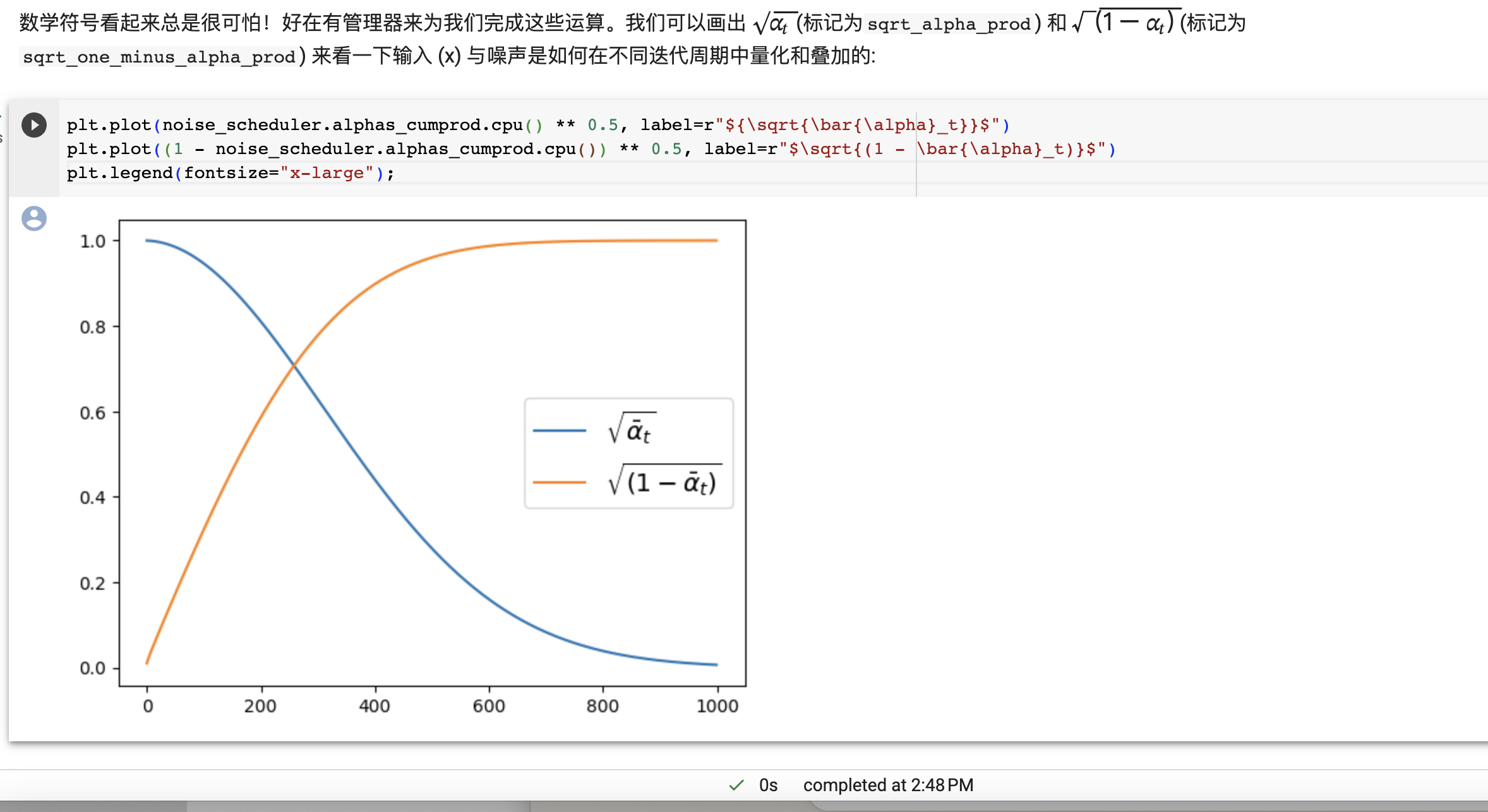
beta_start和beta_end控制的是加噪过程的开始和结束的噪声水平。
- beta_start: 开始训练时添加的噪声量,值越小表示开始时添加的噪声越少。默认是0.0001。
- beta_end: 训练结束时添加的噪声量。默认是0.02。
它们的曲线意义如下: - sqrt(bar{alpha}_t):表示随训练步长增加,去噪的程度,曲线越陡峭表示去噪越快。
- sqrt(1 - bar{alpha}_t):表示残余的噪声量,曲线越低表示最后的噪声越少。
如果beta_start设置得太大,去噪会从一开始就很快,对训练不利;如果beta_end太小,说明最后噪声去除不充分,质量下降。
beta_schedule设置噪声曲线的形状,cosine形状的去噪速度更好更稳定。